Neural networks are widely used to solve image recognition problems: detecting pedestrians and vehicles for self-driving car, identifying people for security systems, identifying gestures for a videogame controller.
I wanted to learn how to use neural networks for image recognition, so I should have a quite large dataset of labeled images to train a neural network. Preparing such a dataset is not an easy job. Hopefully there are open source datasets for different purposes. Most frequently used dataset for image recognition is MNIST (Mixed National Institute of Standards and Technology database). It is a large database of labeled hand-written digits like these:
http://yann.lecun.com/exdb/mnist/
There are many different open source implementations of neural networks, to start from something simple I could use Theano with CUDA to run GPU-powered calculation, but I decided to start from something simple and reliable, so I used Java-based encog library: https://github.com/encog/encog-java-core
It allows thorough configuration of multi-layer neural network architecture and training strategy. For sure it is not fast enough as opposed to C-based implementations or GPU-powered engines, but I didn’t need the fastest implementation right now, I only tried to experiment with network architecture and training.
MNIST database is provided in binary format, so I need custom Java code to parse it into data types supported by encog. I found useful code for this here: https://code.google.com/p/pen-ui/source/browse/trunk/skrui/src/org/six11/skrui/charrec/MNISTReader.java?r=185 and adapted it to create MLDataSet instance.
The simplest code to train a neural network with encog:
// read datasets MLDataSet trainingSet = getDataSet( "c:\\MNIST\\train-labels.idx1-ubyte", "c:\\MNIST\\train-images.idx3-ubyte"); MLDataSet validationSet = getDataSet( "c:\\MNIST\\t10k-labels.idx1-ubyte", "c:\\MNIST\\t10k-images.idx3-ubyte"); // configure the neural network BasicNetwork network = new BasicNetwork(); int hiddenLayerNeuronsCount = 100; network.addLayer(new BasicLayer(null, true, 28*28)); network.addLayer(new BasicLayer(new ActivationElliott(), true, hiddenLayerNeuronsCount)); network.addLayer(new BasicLayer(new ActivationElliott(), false, 10)); network.getStructure().finalizeStructure(); network.reset(); // train the neural network final Propagation train = new ResilientPropagation(network, trainingSet); int epochsCount = 100; for(int epoch = 1; epoch <= epochsCount; epoch++) { train.iteration(); } train.finishTraining(); // calculate error on validation set double error = network.calculateError(validationSet); Encog.getInstance().shutdown(); |
Encog provides implementation of a few different neuron activation functions: BiPolar, BipolarSteepenedSigmoid, ClippedLinear, Competitive, Elliott, ElliottSymmetric, Gaussian, Linear, LOG, Ramp, Sigmoid, SIN, SoftMax, SteepenedSigmoid, Step, TANH.
And a range of training algorithm implementations is available as well: Backpropagation, ManhattanPropagation, QuickPropagation, ResilientPropagation, ScaledConjugateGradient.
I started from training a neural network with one hidden layer. It was hard to choose a correct activation function and training algorithm, therefore I tried all combinations of them on a neural network with one hidden layer with 100 neurons, each neural network being trained in 100 epochs. For each network MSE (mean squared error) on a test set was calculated using encog network.calculateError function.
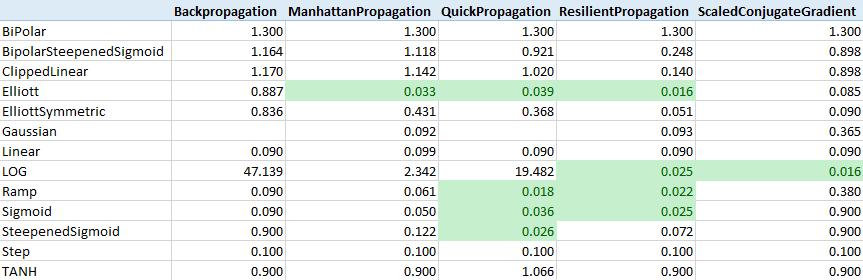
I found that BackPropagation sucks, and that some activation function are not performing well. I tried to compare the numbers with MNIST benchmarks listed on http://yann.lecun.com/exdb/mnist/, and realized that numbers are not comparable, because I calculated MSE and they were apparently calculating error rate as a percentage of wrongly recognized images. So, I excluded a few activation functions from benchmark, and run it again. For each combination of parameters I trained 5 neural networks. Each neural network was trained with 500 epochs, then error rate on test set was calculated. Here are averages of neural network test error rate for each parameter combination:

The best result is 4.21% error rate for LOG activation function and ScaledConjugateGradient training. This result is better than a result for “2-layer NN, 300 hidden units, mean square error”, but worse than all other neural networks listed there. Not bad for the first test.
As I can see here, Backpropagation still sucks for any activation function, ResilientPropagation looks good. All other training types are good for some activation functions and bad for other. ScaledConjugateGradient, which works the best with LOG function, shows extremely bad results (80+ percent errors) for all others.
Training time in minutes:

Training time was measured on a physical machine with Intel Core i5-4440 CPU @ 3.10 GHz. Difference between the fastest and the slowest is about 4 times.
The next steps: check how neural networks with 2 hidden layers work, check how error rate depends on number of neurons in the hidden layer in neural networks with 1 hidden layer.