Deep learning is computationally intensive. Model training and model querying have very different computation complexities. A query phase is fast: you apply a function to a vector of input parameters (forward pass), get results.
Model training is much more intensive. Deep learning requires large training datasets in order to produce good results. Datasets with millions of samples are common now, e.g. ImageNet dataset contains over 1 million images. Training is an iterative process: you do forward pass on each sample of the training set, do backward pass to adjust model parameters, repeat the process a few times (epochs). Thus training requires millions, or even billions more computation than one forward pass, and a model can include billions of parameters to adjust.
An example of time measurements:
“For AlexNet 12, the GPU version does forward pass + backward error propagate for batch size of 128 in about 0.664s. Thus, training ImageNet convolutional network takes about 186 hours with 100 epochs. Caffe reported their forward pass + backward error propagate for batch size of 256 in about 1.3s on NVIDIA TITAN. In the paper, Alex reported 90 epochs within 6 days on two GeForce 580. In “Multi-GPU Training of ConvNets” (Omry Yadan, Keith Adams, Yaniv Taigman, and Marc’Aurelio Ranzato, arXiv:1312.5853), Omry mentioned that they did 100 epochs of AlexNet in 10.5 days on 1 GPU), which suggests my time is within line of these implementations.” http://libccv.org/doc/doc-convnet/
You can run these computations on different devices: CPU, GPU, FPGA. A few years ago CPU was a default choice, but starting from 2012 GPUs are increasingly used in deep learning research.
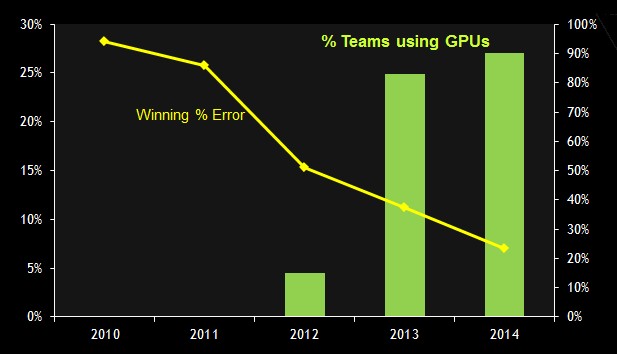
[Image source: http://www.theplatform.net/2015/07/07/nvidia-ramps-up-gpu-deep-learning-performance/]
GPU
Deep learning computation contains mostly matrix operations and is highly parallel by nature, so it can benefit from using GPU. It becomes easier to use as NVIDIA invests a lot into tools like CUDA and CuDNN, and GPU support is added into major deep learning frameworks such as Theano, Torch, Caffe. http://www.theplatform.net/2015/07/07/nvidia-ramps-up-gpu-deep-learning-performance/
Some of the frameworks mentioned above support multiple GPUs.
Torch: https://github.com/torch/cutorch/issues/42
Theano: https://github.com/Theano/Theano/wiki/Using-Multiple-GPUs
Caffe: https://github.com/BVLC/caffe/commit/e5575cf17a43a56e4ba9bc5465548ac0512197d8
Tim Dettmers wrote excellent guides on choosing right hardware for deep learning, focusing on GPU:
https://timdettmers.wordpress.com/2015/03/09/deep-learning-hardware-guide/
https://timdettmers.wordpress.com/2014/08/14/which-gpu-for-deep-learning/
A few interesting quotes:
“It is again and again amazing to see how much speedup you get when you use GPUs for deep learning: Compared to CPUs 10x speedups are typical, but on larger problems one can achieve 20x speedups.”
“Overall, I think memory size is overrated. You can nicely gain some speedups if you have very large memory, but these speedups are rather small. I would say that GPU clusters are nice to have, but that they cause more overhead than the accelerate progress; a single 12GB GPU will last you for 3-6 years; a 6GB GPU is good for now; a 4GB GPU is good but might be limiting on some problems; and a 3GB GPU will be fine for most research that tests new architectures and algorithms on small data sets.”
“Processing performance is most often measured in floating-point operations per second (FLOPS). <…> However, this measure is misleading, as it measures processing power on problems that do not occur in practice.
It turns out that the most important practical measure for GPU performance is bandwidth in GB/s, which measures how much memory can be read and written per second. This is because almost all mathematical operations, such as dot product, sum, addition etcetera, are bandwidth bound, i.e. limited by the GB/s of the card rather than its FLOPS.
To determine the fastest GPU for a given budget one can use this Wikipedia page and look at Bandwidth in GB/s”
“The true beauty of AWS are spot instances: Spot instances are very cheap virtual computers which you usually rent for a couple of hours to run a algorithm and after you have completed your algorithm you shut them down again. For about $1.5 you can rent a AWS GPU spot instance for two hours with which you can run easily 4 experiments on MNIST concurrently and do a total of 160 experiments in that two hours. You can use the same time to run full 8-12 CIFAR-10 or CIFAR-100 experiments.”
Tim’s posts on multi-GPU systems:
https://timdettmers.wordpress.com/2014/10/09/deep-learning-data-parallelism/
https://timdettmers.wordpress.com/2014/11/09/model-parallelism-deep-learning/
If you have no limits on the budget, NVIDIA DIGITS DevBox may be interesting for you. Its price is about $15K. For this money you will get high-end hardware:
“Four TITAN X GPUs with 12GB of memory per GPU
64GB DDR4
Asus X99-E WS workstation class motherboard with 4-way PCI-E Gen3 x16 support
Core i7-5930K 6 Core 3.5GHz desktop processor
Three 3TB SATA 6Gb 3.5” Enterprise Hard Drive in RAID5
512GB PCI-E M.2 SSD cache for RAID
250GB SATA 6Gb Internal SSD
1600W Power Supply Unit from premium suppliers including EVGA”
https://developer.nvidia.com/devbox
http://blogs.nvidia.com/blog/2015/03/17/digits-devbox/
FPGA
Next step in deep learning hardware evolution is probably FPGA. FPGA can be more power efficient.
“FPGAs can achieve an impressive 14 Images/Second/Watt compared to high end GPUs such as Tesla K40, which can get to 4 Images/Second/Watt” http://auvizsystems.com/products/auvizdnn/
Microsoft started experimenting with FPGA for running Bing machine learning algorithms: http://blogs.technet.com/b/inside_microsoft_research/archive/2015/02/23/machine-learning-gets-big-boost-from-ultra-efficient-convolutional-neural-network-accelerator.aspx
“Altera estimates that the floating point throughput will reach 3X the energy efficiency of a comparable GPU. We expect great performance and efficiency gains from scaling our CNN engine to Arria 10, conservatively estimated at a throughput increase of 70% with comparable energy used. We thus anticipate that the new Arria 10 parts will enable an even higher level of efficiency and performance for image classification within Microsoft’s datacenter infrastructure.”
And now they are trying to use Stratix V FPGA devices from Altera for deep learning: http://www.theplatform.net/2015/08/27/microsoft-extends-fpga-reach-from-bing-to-deep-learning/
These FPGA use 14-nanometer process, which is better than current 28-nanometer process of NVIDIA chips. Energy efficiency gap between GPU and FPGA can change a bit when NVIDIA releases 16nm Pascal graphics card.
Google is rumored to experiment with FPGA too:
“LeCun told The Platform that Google is rumored to be building custom hardware to run its neural networks and that this hardware is said to be based on FPGAs” http://www.theplatform.net/2015/08/25/a-glimpse-into-the-future-of-deep-learning-hardware/
FPGA looks like a good way to optimize energy consumption of a data center, but it is much harder to program, so GPU still can be a better choice for individual researchers and companies smaller than Microsoft and Google.
A glimpse into the future of deep learning hardware: http://www.theplatform.net/2015/08/25/a-glimpse-into-the-future-of-deep-learning-hardware/
Cars
Self-driving cars is one of the most interesting applications of deep learning. NVIDIA wants to contribute to this industry, so it is developing a specialized car computer NVIDIA DRIVE PX http://blogs.nvidia.com/blog/2015/03/17/nvidia-drive-px/
It is powered by two Tegra X1 chips, 2.3 teraflops each. Camera input processing throughput is enough to handle 12 2-megapixel cameras with up to 60fps rates.
Mobile
Though model training is still better to do in the cloud or at least on a desktop machine with powerful GPU, it is possible to execute trained models on end-user devices like smartphones. It is still tricky because you might want to allow users with low-end devices to run your applications.
Google describes how they moved letter recognition from the cloud to Android devices: http://googleresearch.blogspot.com/2015/07/how-google-translate-squeezes-deep.html
“Now, if we could do this visual translation in our data centers, it wouldn’t be too hard. But a lot of our users, especially those getting online for the very first time, have slow or intermittent network connections and smartphones starved for computing power. These low-end phones can be about 50 times slower than a good laptop—and a good laptop is already much slower than the data centers that typically run our image recognition systems. So how do we get visual translation on these phones, with no connection to the cloud, translating in real-time as the camera moves around?”
I think in near future we will see how deep learning increasingly moves from data centers to smartphones, tablets and smartwatches, starting from things which require near real-time performance. Smartphones may get deep learning optimized GPU chips. FPGA and ASIC chips may get more software support and become mainstream. It will be interesting.