Text summarization problem has many useful applications. If you run a website, you can create titles and short summaries for user generated content. If you want to read a lot of articles and don’t have time to do that, your virtual assistant can summarize main points from these articles for you.
It is not an easy problem to solve. There are multiple approaches, including various supervised and unsupervised algorithms. Some algorithms rank the importance of sentences within the text and then construct a summary out of important sentences, others are end-to-end generative models.
End-to-end machine learning algorithms are interesting to try. After all, end-to-end algorithms demonstrate good results in other areas, like image recognition, speech recognition, language translation, and even question-answering.
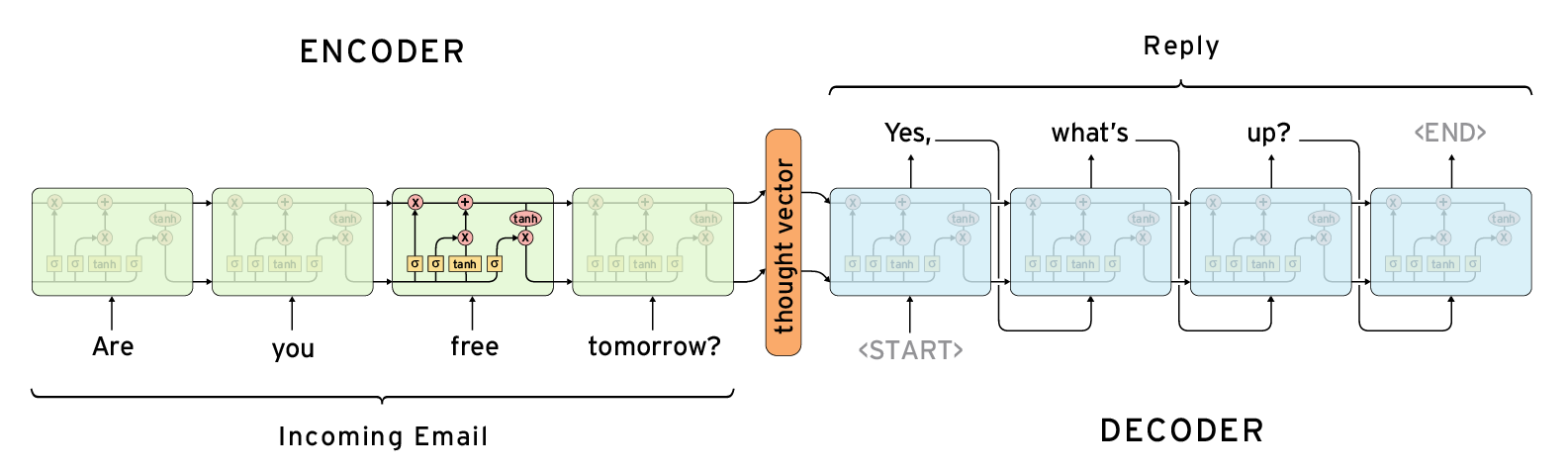
Text summarization with TensorFlow
In August 2016, Peter Liu and Xin Pan, software engineers on Google Brain Team, published a blog post “Text summarization with TensorFlow”. Their algorithm is extracting interesting parts of the text and create a summary by using these parts of the text and allow for rephrasings to make summary more grammatically correct. This approach is called abstractive summarization.
Peter and Xin trained a text summarization model to produce headlines for news articles, using Annotated English Gigaword, a dataset often used in summarization research. The dataset contains about 10 million documents. The model was trained end-to-end with a deep learning technique called sequence-to-sequence learning.
Code for training and testing the model is included into TensorFlow Models GitHub repository. The core model is a sequence-to-sequence model with attention. When training, the model is using the first two sentences from the article as an input and generates a headline.
When decoding, the algorithm is using beam search to find the best headline from candidate headlines generated by the model.
GitHub repository doesn’t include a trained model. The dataset is not publicly available, a license costs $6000 for organizations which are not members of Linguistic Data Consortium. But they include a toy dataset which is enough to run the code.
How to run
You will need TensorFlow and Bazel as prerequisites for training the model.
The toy dataset included into the repository, contains two files in “data” directory: “data” and “vocab”. The first one contains a sequence of serialized tensorflow.core.example.example_pb2.Example objects. An example of code to create a file with this format:
import struct
from tensorflow.core.example import example_pb2
with open(output_filename, 'wb') as writer:
body = 'body'
title = 'title'
tf_example = example_pb2.Example()
tf_example.features.feature['article'].bytes_list.value.extend([body])
tf_example.features.feature['abstract'].bytes_list.value.extend([title])
tf_example_str = tf_example.SerializeToString()
str_len = len(tf_example_str)
writer.write(struct.pack('q', str_len))
writer.write(struct.pack('%ds' % str_len, tf_example_str)) |
“vocab” file is a text file with the frequency of words in a vocabulary. Each line contains a word, space character and number of occurrences of that word in the dataset. The list is being used to vectorize texts.
Running the code on toy dataset is really simple. Readme on GitHub repo lists a sequence of commands to run training and testing code.
You can run TensorBoard to monitor training process:
When running “decode” code, note that it will loop over the entire dataset indefinitely, so you will have to stop execution manually at some point. You can find results of decoding in log_root/decode folder. It will contain a few files, some of them have prefix “ref”, they contain original headlines from the test set. Other files have prefix “decode”, they contain headlines generated by the model.
Troubleshooting
You can encounter an error when running “eval” or “decode” code using TensorFlow 0.10 or later:
“ValueError: Could not flatten dictionary. Key had 2 elements, but value had 1 elements.”
There is an open issue on GitHub for this error. One workaround is to downgrade TensorFlow to 0.9, it worked for me. Another workaround requires changing the code of the model: adding “state_is_tuple=False” to instantiations of LSTMCell in seq2seq_attention_model.py.
If you run training and decoding on toy dataset, you will notice that decoding generates nonsense. Here are few examples of headlines generated:
<UNK> to <UNK> <UNK> <UNK> <UNK> <UNK> .
<UNK> <UNK> <UNK> <UNK> of <UNK> <UNK> from <UNK> <UNK> .
in in <UNK> <UNK> <UNK> .
One of the reasons for poor performance on the toy set could be incompleteness of the vocabulary file. Vocabulary file is truncated and doesn’t contain many of the words which are used in the “data” file. It leads to too many “<UNK>” tokens which represent unknown words.
How to run on another dataset
A toy dataset is, well, a toy. To create a useful model you should train it on a large dataset. Ideally, the dataset should be specific for your task. Summarizing news article may be different from summarizing legal documents or job descriptions.
As I don’t have access to GigaWord dataset, I tried to train the model on smaller news article datasets, which are free: CNN and DailyMail. I found the code to download these datasets in DeepMind/rcdata GitHub repo, and slightly modified it to add the title of the article in the first line of each output file. See modified code here.
92570 articles in CNN dataset, and 219503 articles in Daily Mail dataset. It could be a few more articles, but the code from DeepMind repo could not download all URLs. 322k articles are way fewer than 10 million articles in GigaWord, so I would expect a lower performance of the model if training on these datasets.
After you run the code to download the dataset you will have a folder with lots of files, one HTML file for every article. To use it in TextSum model you will need to convert it to the binary format described above. You can find my code to convert CNN/DailyMail articles into binary format in textsum_data_convert.py file in my “TextSum” repo on GitHub. An example of running the code for CNN dataset:
python textsum_data_convert.py \ --command text_to_vocabulary \ --in_directories cnn/stories \ --out_files cnn-vocab python textsum_data_convert.py \ --command text_to_binary \ --in_directories cnn/stories \ --out_files cnn-train.bin,cnn-validation.bin,cnn-test.bin \ --split 0.8,0.15,0.05
Then you can copy train/validation/test sets and vocabulary files into “data” directory and start training the model:
Train on CNN data (cnn-train, cnn-vocab): bazel-bin/textsum/seq2seq_attention \ --mode=train \ --article_key=article \ --abstract_key=abstract \ --data_path=data/cnn-train.bin \ --vocab_path=data/cnn-vocab.bin \ --log_root=log_root \ --train_dir=log_root/train \ --truncate_input=True Evaluate on CNN data (cnn-validation, cnn-vocab): bazel-bin/textsum/seq2seq_attention \ --mode=eval --article_key=article \ --abstract_key=abstract \ --data_path=data/cnn-validation.bin \ --vocab_path=data/cnn-vocab.bin \ --log_root=log_root \ --train_dir=log_root/eval \ --truncate_input=True Decode on CNN data (cnn-test, cnn-vocab): bazel-bin/textsum/seq2seq_attention \ --mode=decode \ --article_key=article \ --abstract_key=abstract \ --data_path=data/cnn-test.bin \ --vocab_path=data/cnn-vocab.bin \ --log_root=log_root \ --decode_dir=log_root/decode \ --beam_size=8 \ --truncate_input=True
Training with default parameters doesn’t go very well. Here is a graph of running_avg_loss:
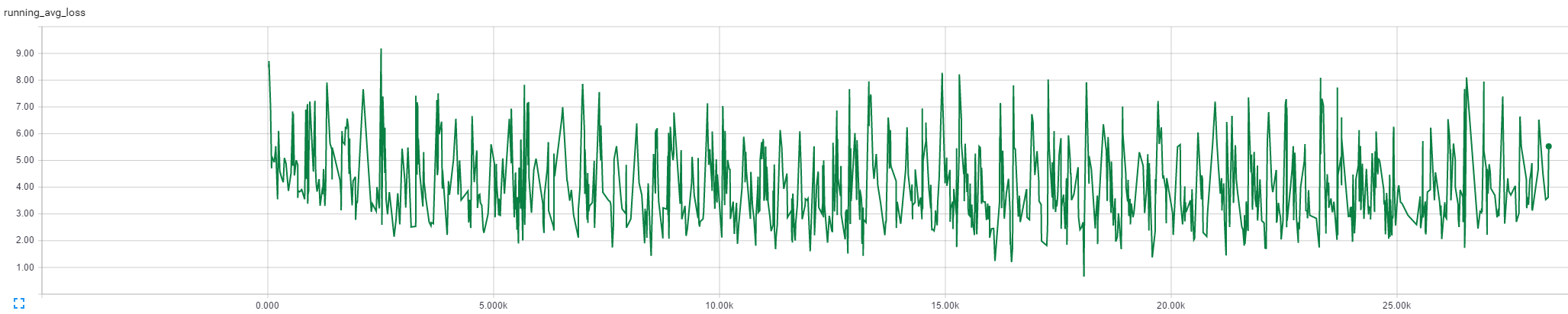
Decoding results are also disappointing:
“your your <UNK>”
“We’ll the <UNK>”
“snow hit hit hit <UNK>”
Either dataset is too small, or hyperparameters need to be changed for this dataset.
When running the code I found that training code doesn’t use GPU, though I have all the correct configuration: GeForce 980Ti, CUDA, CuDNN, TensorFlow compiled with using GPU. While training, python.exe consumes 100–300+% CPU, and it appears in the list of processes when running nvidia-smi, but GPU utilization stays 0%.
Thu Oct 13 20:14:11 2016 +------------------------------------------------------+ | NVIDIA-SMI 352.39 Driver Version: 352.39 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 GeForce GTX 980 Ti Off | 0000:01:00.0 Off | N/A | | 29% 46C P8 26W / 250W | 124MiB / 6142MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | 0 17605 C /usr/bin/python 102MiB | +-----------------------------------------------------------------------------+
I guess it can be related to the fact that authors of the model were running the code using multiple GPUs, and one GPU had some special purpose. A fragment of seq2seq_attention_model.py file:
def _next_device(self):
"""Round robin the gpu device. (Reserve last gpu for expensive op)."""
if self._num_gpus == 0:
return ''
dev = '/gpu:%d' % self._cur_gpu
self._cur_gpu = (self._cur_gpu + 1) % (self._num_gpus-1)
return dev |
The decoding code uses GPU quite well. It consumes almost all 6Gb of GPU memory and keeps utilization over 50%.
Sat Oct 15 01:51:04 2016 +------------------------------------------------------+ | NVIDIA-SMI 352.39 Driver Version: 352.39 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 GeForce GTX 980 Ti Off | 0000:01:00.0 Off | N/A | | 32% 53C P2 96W / 250W | 5881MiB / 6142MiB | 56% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | 0 3020 C /usr/bin/python 5858MiB | +-----------------------------------------------------------------------------+
Conclusion
Using the code from this article you can easily run text summarization model on your own dataset. Let me know if you find something interesting!
If you happen to have a license for the GigaWord dataset, I will be happy if you share trained TensorFlow model with me. I would like to try it on some proprietary data, not from news articles.
Do you use any other text summarization algorithms? What works the best?