Machine intelligence field grows with breakneck speed since 2012. That year Alex Krizhevsky, Ilya Sutskever and Geoffrey E. Hinton achieved the best result in image classification on LSVRC-2010 ImageNet dataset using convolutional neural networks. It’s amazing that end-to-end training of a deep neural network worked better than sophisticated computer vision systems with handcrafted feature engineering pipelines being refined by researchers for decades.
Since then deep learning field got the attention of machine learning researchers, software engineers, entrepreneurs, venture investors, even artists and musicians. Deep learning algorithms surpassed the human level of image classification and conversational speech recognition, won Go match versus 18-time world champion. Every day new applications of deep learning emerge, and tons of research papers are published. It’s hard to keep up. We live in a very interesting time, future is already here.
Deep learning is rapidly moving from research labs to the industry. Google had 2700+ projects using deep learning in 2015.
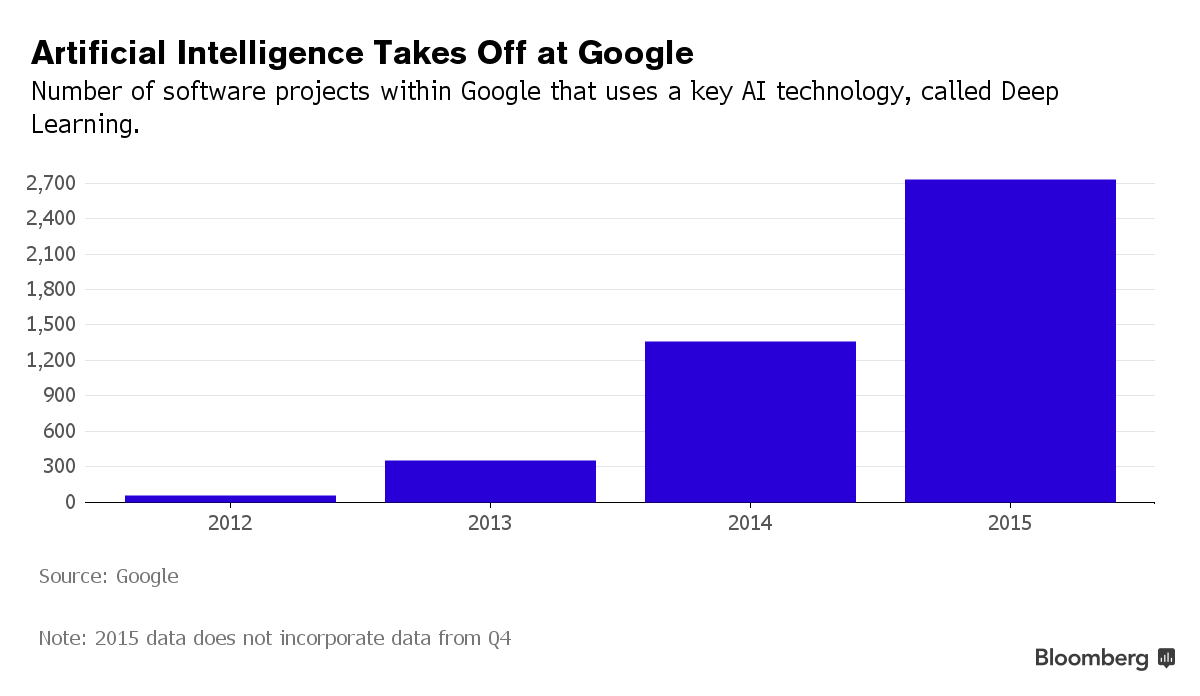 Image credit: https://www.bloomberg.com/news/articles/2015-12-08/why-2015-was-a-breakthrough-year-in-artificial-intelligence
Image credit: https://www.bloomberg.com/news/articles/2015-12-08/why-2015-was-a-breakthrough-year-in-artificial-intelligence
A neural network is only one layer of an intelligent application. If you look at a typical deep learning system, it includes hardware (CPU, GPU, FPGA), drivers, programming languages, libraries, models, etc. Almost no company can develop the entire stack alone, the work should be divided between multiple organizations and multiple teams inside of an organization. It is natural to structure computer systems in layers, from bare metal in the bottom to more abstract layers on the top. If interfaces between layers are stable and well defined, it is easy for engineers to focus on one of the layers and reuse lower layers developed by someone else.
There is no stable intelligence platform stack yet, it is open for interpretation and changes. Most common model of the stack includes 8 layers, from hardware in the bottom to an application layer on the top. Layers from the bottom up:
1. Hardware to accelerate computation. Typically it is multi-core CPU or GPU. GPUs are much more powerful than CPUs for deep learning applications. Thanks to gamers who paid for the progress on GPU engineering. Now there are companies working on hardware which is more power efficient than GPUs: FPGA and ASIC chips. For example, Google is using special chips named TPU (tensor processing unit) in their data centers.
Companies working on this layer: NVIDIA, Intel, Altera (acquired by Intel), Google (tensor processing unit).
2. Hardware abstraction. NVIDIA CUDA and CuDNN provide functionality for training and inference of neural networks on NVIDIA GPU.
3. Programming language. Developers need to use a programming language to do data preprocessing, model training, inference. Python is the most popular language for deep learning, at least for training, because there are very good scientific computing libraries for Python. C++, Lua, R are also being used, though less than Python.
4. Deep learning libraries/frameworks. Perhaps the most important layer. It contains means for expressing deep learning models and often contains algorithms for auto-differentiation and optimization. Theano, Torch, and Caffe have been used by researchers and engineers a lot. In 2015 Google released TensorFlow, and it quickly became the most popular framework for deep learning. A few more recently released libraries: CNTK (Microsoft), Warp-CTC (Baidu).
All these frameworks have different levels of abstraction, e.g. Theano has auto-diff but doesn’t have built-in code for popular types of neural networks (LSTM, CNN), so you will need to program neural network code yourself or use higher level frameworks which work on top of Theano, e.g. Keras.
The libraries have different characteristics for use in a production environment: TensorFlow provides very efficient C++ based TensorFlow Serving component which can do inference, Theano doesn’t have anything like that.
5. Neural network architecture. There are lots of different ways how you can configure a neural network: which types of neurons you use, how many layers and neurons, regularization techniques. See a catalog of architectures in Neural Network Zoo.
Neural networks tend to get larger and more sophisticated. AlexNet had 8 learned layers, more recent ResNet networks from Microsoft researchers use 200-1000 layers.
Recent neural network models also are more complex and modular than earlier architectures. A Dynamic Memory Network model, presented by Richard Socher at Bay Area Deep Learning School 2016 contains 5 modules:
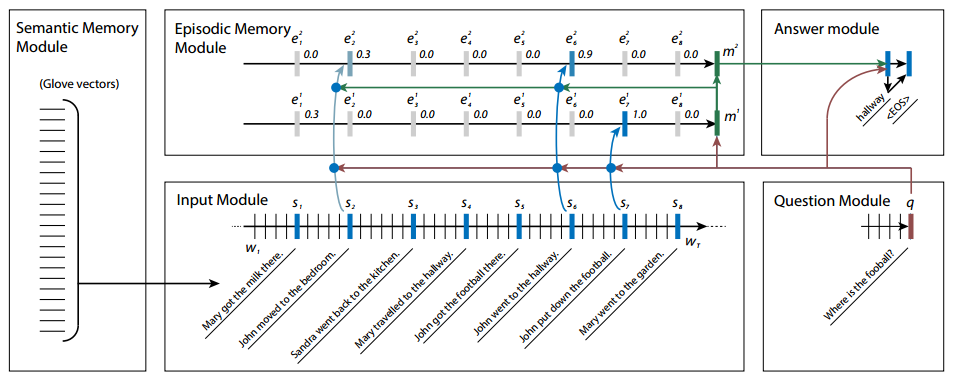
Image credit: http://media.wix.com/ugd/142eb4_7581cfcf090e4e31a52599315f77c648.pdf
This is an area of active research: Google, Facebook, Baidu, Microsoft, Stanford, University of Toronto and others.
6. Cognitive architecture. A few neural networks and other kinds of AI modules can be combined to support smarter reasoning. Deep learning models which extract meaning from the text can work together with symbolic computation, use predefines rules and knowledge bases to get to deeper levels of text understanding. Supervised learning models can be combined with unsupervised learning models to use unlabeled data better. Large neural networks can be split into smaller neural networks trained and configured separately. This area is quite interesting, and there are more problems than solutions here yet.
7. Machine learning as a service. Cloud APIs for machine learning, e.g. Google Vision API, Google Cloud ML. The chatbot ML services wit.ai, api.ai, luis.ai are in this category too.
8. Application. An application which is accessible by end users and provides business value.
Related links:
- Anatoly Levenchuk about intelligence platform stack: September 2016, September 2015, August 2015
- GPU platforms set to lengthen deep learning reach
- What’s Missing in AI: The Interface Layer
What layers are you working on? Please share in comments!