Text summarization problem has many useful applications. If you run a website, you can create titles and short summaries for user generated content. If you want to read a lot of articles and don’t have time to do that, your virtual assistant can summarize main points from these articles for you.
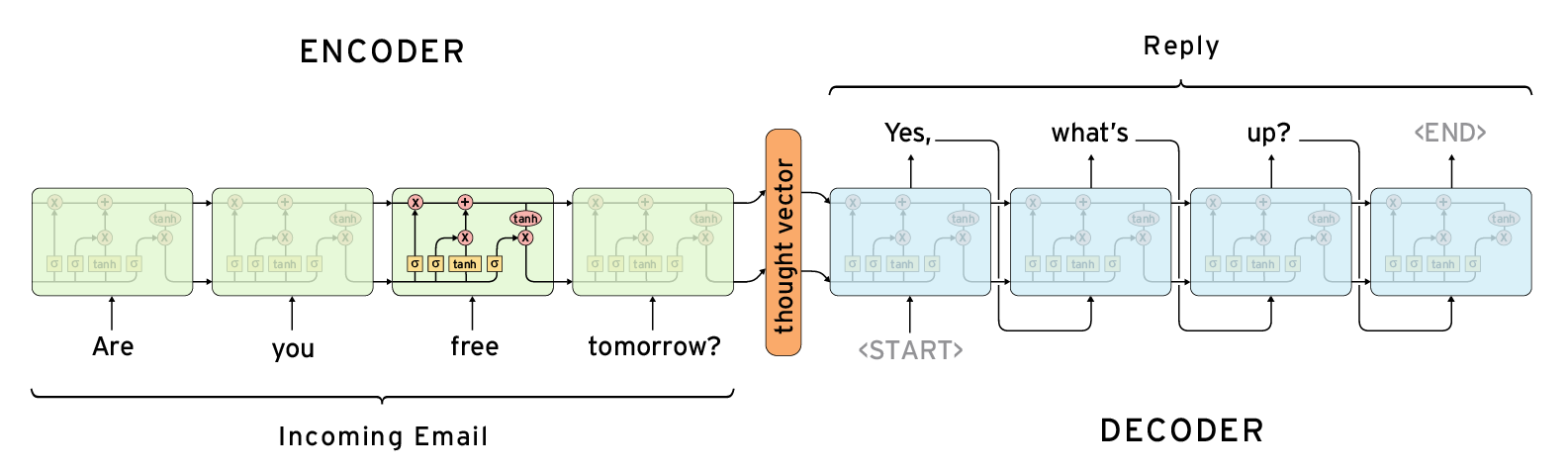
It is not an easy problem to solve. There are multiple approaches, including various supervised and unsupervised algorithms. Some algorithms rank the importance of sentences within the text and then construct a summary out of important sentences, others are end-to-end generative models.
End-to-end machine learning algorithms are interesting to try. After all, end-to-end algorithms demonstrate good results in other areas, like image recognition, speech recognition, language translation, and even question-answering.